Learning End-to-End Lossy Image Compression: A Benchmark
Highlights
-
grade We conduct a comprehensive survey and benchmark on existing end-to-end learned image compression methods. We summarize the merits of existing works, where we specifically focus on the design of network architectures and entropy models.
-
grade We analyze the proposed coarse-to-fine hyperprior model for learned image compression in further details. The training code in PyTorch is now available at GitHub. Code for further analysis will be available soon.
-
grade We benchmarked the rate-distortion performances of a series of existing methods. The results are presented in R-D curves and BD-rates.
-
grade We further conduct a cross-metric evaluation on all benchmarked methods. Models optimized by MSE or MS-SSIM have different characteristics. We observed a metric-related bias introduced by the rate-distortion optimization.
Coarse-to-Fine Hyperprior Analysis
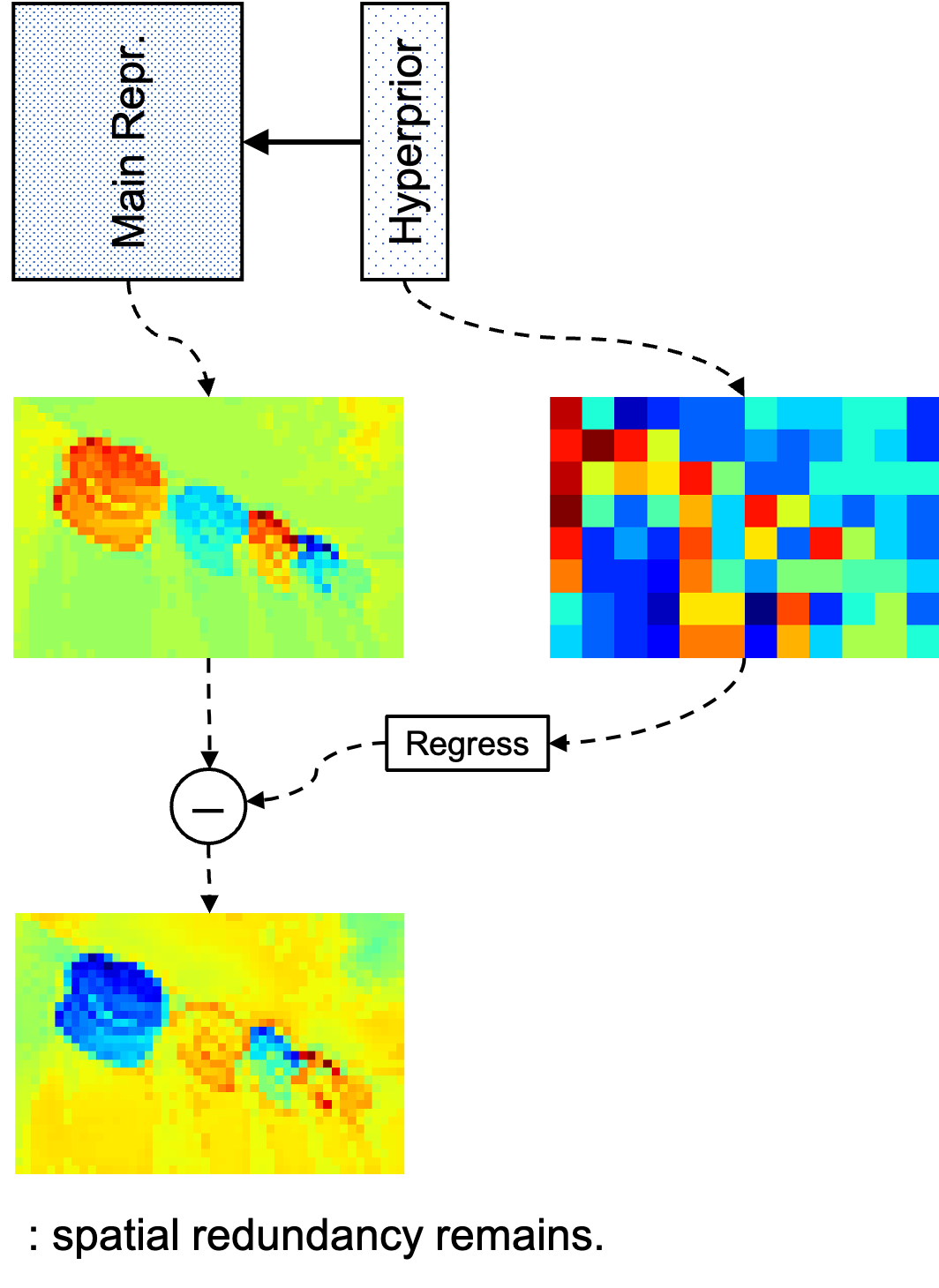
grade With the visualization of the main latent representations (Main Repr.) and the hyperprior representations shown above, we observe that though elements in the main representation are assumed to be conditionally independently distributed, such assumption may not hold. Even with the conditional hyperprior, spatial redundancy is observed.
grade
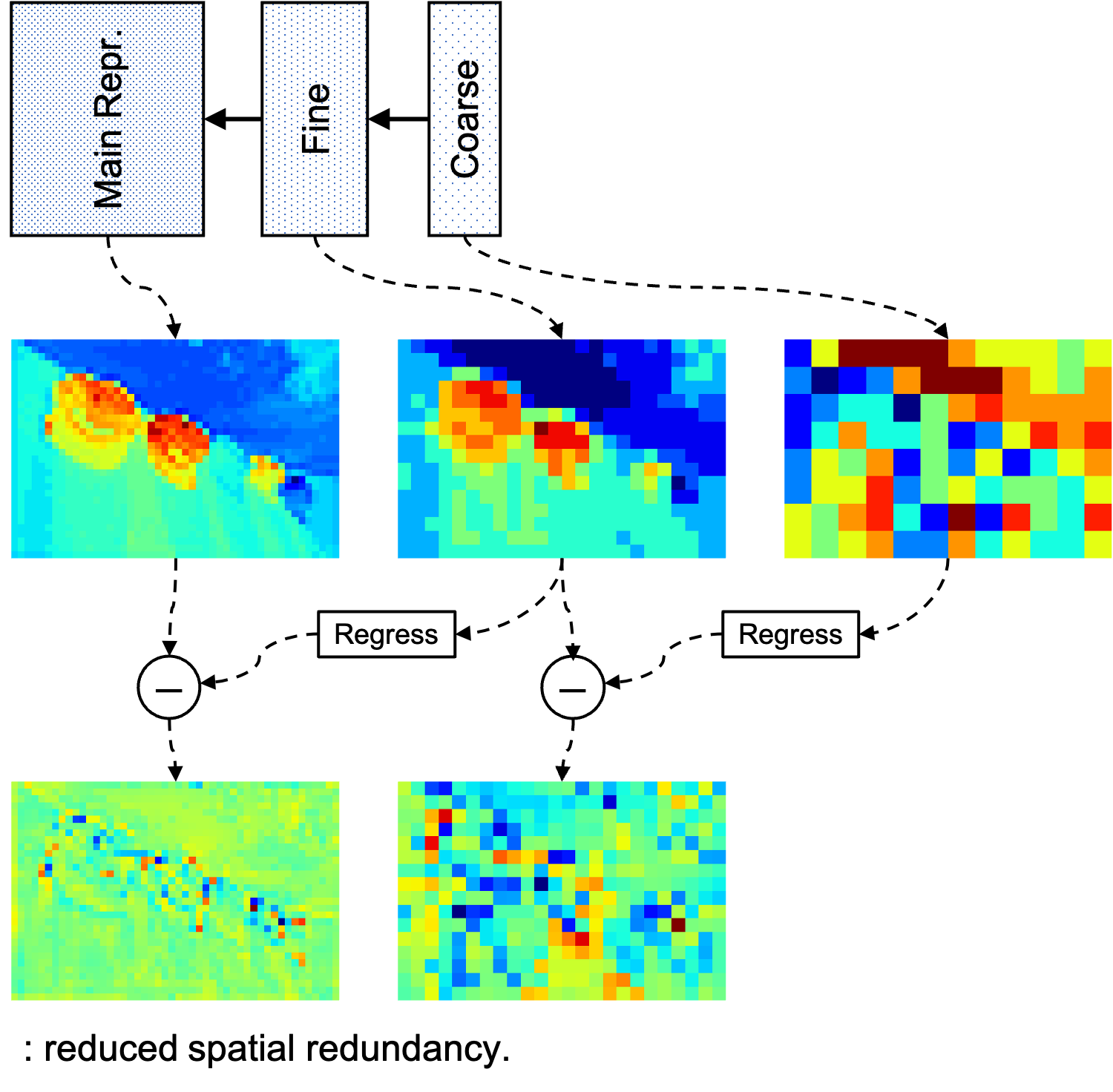
We first introduce a fine-grained hyperprior (Fine) to more accurately model
the joint probability density. As shown, the residual contains less spatial redundancy, indicating
that the fine hyperprior reduces the redundancy in the main representation.
grade As the dimensionality of the fine-grained hyperprior is enlarged, its spatial redundancy inevitably
increases. We therefore design a coarse-grained hyperprior (Coarse) as the second-order latent variable of the
fine-grained hyperprior. It captures the spatial correlations in the fine-grained hyperprior and helps
reduce the bit-rate of the fine-grained hyperprior.
Please check our paper for quantitative ablation study results.
Benchmark
Datasets
[Kodak]E. Kodak, "Kodak lossless true color image suite (PhotoCD PCD0992)".
URL: http://r0k.us/graphics/kodak/
[Tecnick] Asuni, Nicola and Giachetti, Andrea, "TESTIMAGES:
a Large-scale Archive for Testing Visual Devices and Basic Image Processing Algorithms,"
Eurographics Italian Chapter Conference, 2014.
URL: https://testimages.org/sampling/
(40 images with resolution 1200x1200 are used.)
[CLIC 19] CLIC: Workshop and Challenge on Learned Image Compression.
URL: http://www.compression.cc/2019/challenge/
(The professional and mobile validation sets are used.)
[LIU4K]Jiaying Liu, Dong Liu, Wenhan Yang, Sifeng Xia, Xiaoshuai Zhang, and Yueying Dai.
"A Comprehensive Benchmark for Single Image Compression Artifact Reduction",
IEEE Transactions on Image Processing, 2020.
URL: https://flyywh.github.io/LIU4K_Website/
These images in the testing set
Methods
[VTM-8] Test Model 8 for Versatile Video Coding
URL: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM.git
[PCS-18] J. Ball´e, "Efficient nonlinear transforms for lossy image compression,"
in Proc. of Picture Coding Symposium, 2018.
URL: https://github.com/tensorflow/compression
[ICLR-18] J. Ball´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston,
"Variational image compression with a scale hyperprior," in Proc.
of International Conference on Learning Representations, 2018.
URL: https://github.com/tensorflow/compression
[NeurIPS-18] D. Minnen, J. Ball´e, and G. D. Toderici, "Joint autoregressive and
hierarchical priors for learned image compression," in Proc. of
Advances in Neural Information Processing Systems, 2018.
URL: https://github.com/tensorflow/compression
[ICLR-19] J. Lee, S. Cho, and S.-K. Beack, "Context adaptive entropy model
for end-to-end optimized image compression," in Proc.
of International Conference on Learning Representations, 2019.
URL: https://github.com/JooyoungLeeETRI/CA_Entropy_Model
[CVPR-17] G. Toderici, D. Vincent, N. Johnston, S. Jin Hwang, D. Minnen,
J. Shor, and M. Covell, "Full resolution image compression with
recurrent neural networks," in Proc. IEEE Conference on Computer
Vision and Pattern Recognition, 2017.
URL: https://github.com/nmjohn/models/tree/master/compression
[CVPR-18] F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and
L. Van Gool, "Conditional probability models for deep image
compression," in Proc. of IEEE Conference on Computer Vision and
Pattern Recognition, 2018.
URL: https://github.com/fab-jul/imgcomp-cvpr
Please check our paper for quantitative evaluation and comparison.
Further Details
For details please refer to the paper on arXiv.